Software Design¶
MVC Model¶
A standard architecture for software has become a form of an observer pattern called Model-View-Controller (MVC)-Model [3]. This is escpecially true for web-based applications that use some form of a client-server architecture since these systems naturally divide the browser view from the rest of the program logic and, if dynamically set up, also from the data model usually running in an extra server as well. As already implied, the MVC-pattern modularizes the program into three components: model, view, and controller coupled low by interfaces. The view is concerned with everything the actual user sees on the screen or uses to interact with the machine. The controller is to recognize and process the events initiated by the user and to update the view. Processing involves to communicate with the model. This may involve to save or provide data from the data base.
From all that follows, MVC-models are especially supportive for reusing existing software and promotes parallel development of its three components. So the data model of an existing program can easily be changed without touching the essentials of the program logic. The same is true for the code that handles the view. Most of the time view and data model are the two components that need to be changed so that the software appearance and presentation is adjusted to the new user group as well as the different data is adjusted to the needs of the different requirements of the new application. Nevertheless, if bugs or general changes in the controller component have to be done, it usually does not affect substantially the view and data model.
Another positive consequence of MVC-models is that several views (or even models) could be used simultaneously. It means that the same data could be presented differently on the user interface.
Morphilo Architecture¶
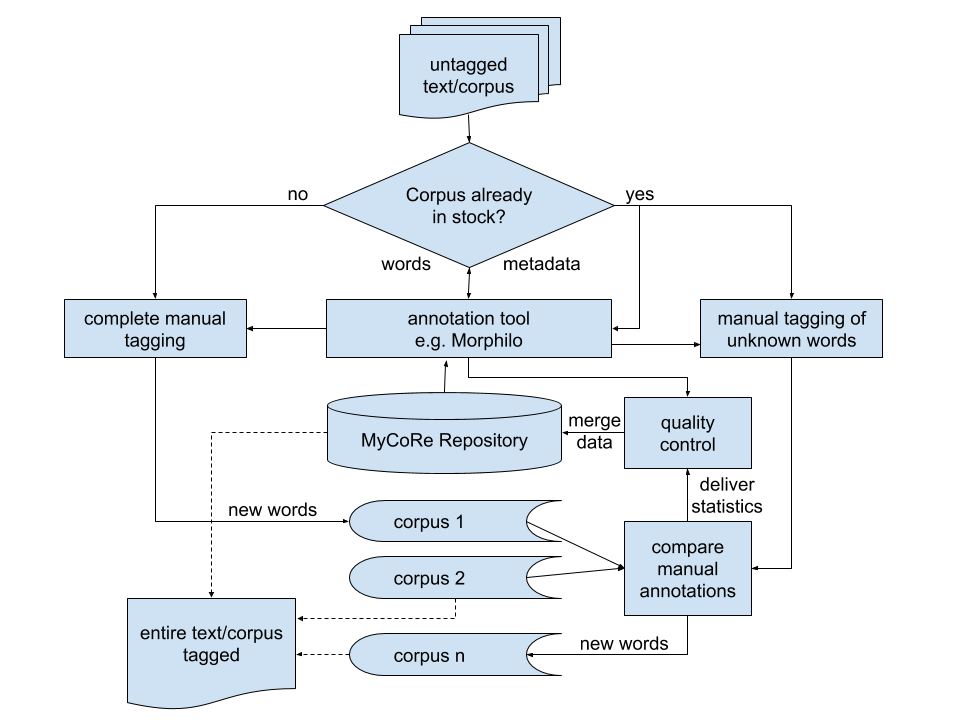
Figure 1: Basic Architecture of a Take-&-Share-Approach
The architecture of a possible take-and-share approach for language resources is visualized in figure 1. Because the very gist of the approach becomes clearer if describing a concrete example, the case of annotating lexical derivatives of Middle English with the help of the Morphilo Tool [1] using a MyCoRe repository is given as an illustration. However, any other tool that helps with manual annotations and manages metadata of a corpus could be substituted here instead. [2]
After inputting an untagged corpus or plain text, it is determined whether the input material was annotated previously by a different user. This information is usually provided by the metadata administered by the annotation tool; in the case at hand, the Morphilo component. An alternative is a simple table look-up for all occurring words in the datasets Corpus 1 through Corpus n. If contained completely, the yes-branch is followed up further – otherwise no succeeds. The difference between the two branches is subtle, yet crucial. On both branches, the annotation tool (here Morphilo) is called, which, first, sorts out all words that are not contained in the master database (here MyCoRe repository) and, second, makes reasonable suggestions on an optimal annotation of the items. The suggestions made to the user are based on simple string mapping of a saved list of prefixes and suffixes whereas the remainder of the mapping is defined as the word root. The annotations are linked to the respective items (e.g. words) in the text, but they are also persistently saved in an extra dataset, i.e. in figure 1 in one of the delineated Corpus 1 through n, together with all available metadata.
The difference between the two branches in figure 1 is that in the yes-branch a comparison between the newly created dataset and all of the previous datasets of this text is carried out while this is not possible if a text was not annotated before. Within this unit, all deviations and congruencies of the annotated items are marked and counted. The underlying assumption is that with a growing number of comparable texts the correct annotations approach a theoretic true value of a correct annotation while errors level out provided that the sample size is large enough. How the distribution of errors and correct annotations exactly looks like and if a normal distribution can be assumed is still object of the ongoing research, but independent of the concrete results, the component (called compare manual annotations in figure 1) allows for specifying the exact form of the sample population. In fact, it is necessary at that point to define the form of the distribution, sample size, and the rejection region. To be put it simple here, a uniform distribution in form of a threshold value of e.g. 20 could be defined that specifies that a word has to be annotated equally by 20 different users before it enters the master database.
Continuing the information flow in figure 1 further, the threshold values or, if so defined, the results of the statistical calculation of other distributions respectively are delivered to the quality-control-component. Based on the statistics, the respective items together with the metadata, frequencies, and, of course, annotations are written to the master database. All information in the master database is directly used for automated annotations. Thus it is directly matched to the input texts or corpora respectively through the Morphilo-tool. The annotation tool decides on the entries looked up in the master which items are to be manually annotated.
The processes just described are all hidden from the user who has no possibility to impact the set quality standards but by errors in the annotation process. The user will only see the number of items of the input text he or she will process manually. The annotator will also see an estimation of the workload beforehand. On this number, a decision can be made if to start the annotation at all. It will be possible to interrupt the annotation work and save progress on the server. And the user will have access to the annotations made in the respective dataset, correct them or save them and resume later. It is important to note that the user will receive the tagged document only after all items are fully annotated. No partially tagged text can be output.
Repository Framework¶
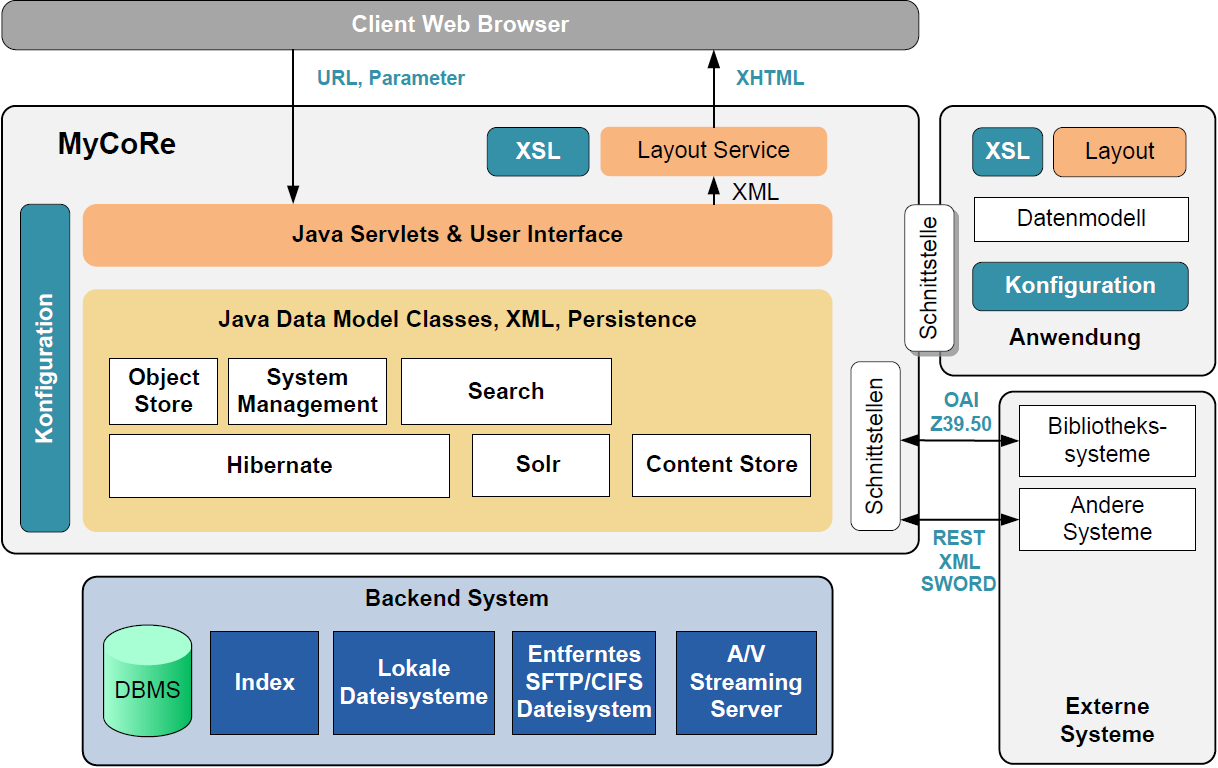
Figure 2: MyCoRe-Architecture and Components
To specify the repository framework, the morphilo application logic will have to be implemented, a data model specified, and the input, search and output mask programmed.
There are three directories which are important for adjusting the MyCoRe framework to the needs of one’s own application.
These three directories correspond essentially to the three components in the MVC model as explicated above. Roughly, they are also envisualized in figure 2 in the upper right hand corner. More precisely, the view (Layout in figure 2) and the model layer (Datenmodell in figure 2) can be done completely via the interface, which is a directory with a predefined structure and some standard files. For the configuration of the logic an extra directory is offered (/src/main/java/custom/mycore/addons/). Here all, java classes extending the controller layer should be added. Practically, all three MVC layers are placed in the src/main/-directory of the application. In one of the subdirectories, datamodel/def, the datamodel specifications are defined as xml files. It parallels the model layer in the MVC pattern. How the data model was defined will be explained in the section Data Model.
Notes
| [1] | Peukert, H. (2012): From Semi-Automatic to Automatic Affix Extraction in Middle English Corpora: Building a Sustainable Database for Analyzing Derivational Morphology over Time, Empirical Methods in Natural Language Processing, Wien, Scientific series of the ÖGAI, 413-23. |
| [2] | The source code of a possible implementation is available on https://github.com/amadeusgwin/morphilo. The software runs in test mode on https://www.morphilo.uni-hamburg.de/content/index.xml. |
| [3] | Butz, Andreas; Antonio Krüger (2017): Mensch-Maschine-Interaktion, De Gruyter, pp. 93. |